Like everyone else helping customers navigate the fast moving waters of Data and AI, I have been following the new technologies and products that are springing up around Generative AI. The thing that has struck me as most profound is how the conversation is really being led by the hyperscalers. Sure OpenAI was the first vendor to break the technology, but with their Microsoft Partnership they quickly became part of the Hyperscaler arms race. Amazon followed with Bedrock and Google with Bard and Vertex and while there are lots of niche players, it’s clear that the cloud providers will play the pivitol role.
This struck me as interesting because it represents a shift for the hyperscalers from being infrastructure companies that occasionally sell a platform to being true platform companies where almost no one comes to them for “just” infrastructure. Relatively few firms (outside of technology companies) are trying to build their Generative AI stack from scratch without leveraging the ecosystem of one of the hyperscalers which makes those hyperscalers competition more with Teradata or Cloudera then Dell or Nvidia. While this sticks out in Generative AI because it’s new and there aren’t any established players, it’s actually a trend that has been gradually emerging across data and AI (other places as well, but that’s not my focus today).
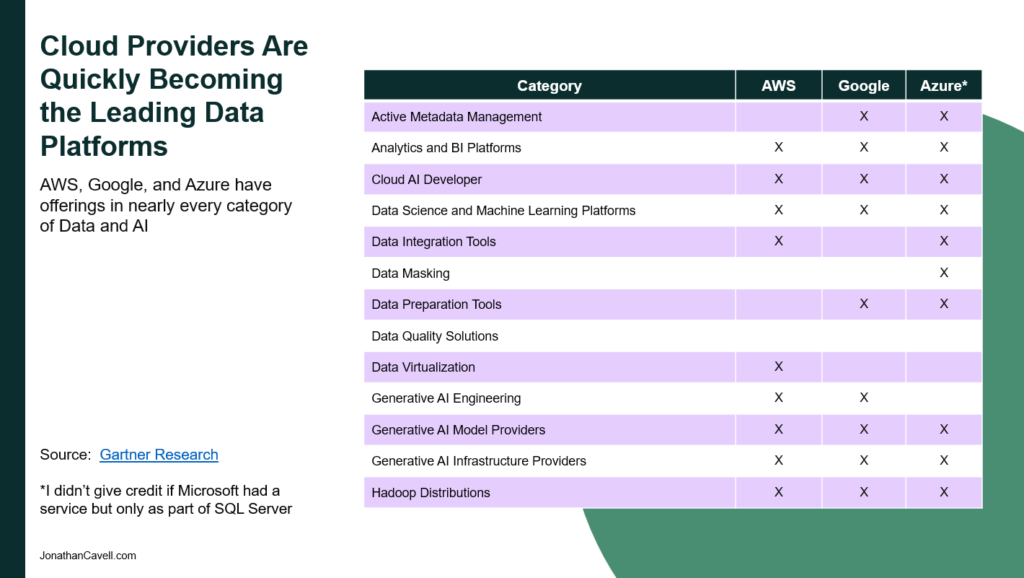
I’ve noticed the trickle releases of Azure Fabric, Amazon Sagemaker, and the dozens and dozens of other data tools released by the hyperscalers, but it wasn’t until I was preparing this article that I realized how complete the hyperscaler offerings have become. Take a look at the chart above on “Cloud Platforms are Quickly Becoming the Leading Data Platform Providers”. I looked at Gartner’s major data categories and mapped where there were offerings from each provider. You’ll notice that the hyperscalers actually have enough data technology that for many use cases you don’t need Cloudera or Teradata or even niche add-ons like data masking. The only clear exception I noticed was in Data Quality.
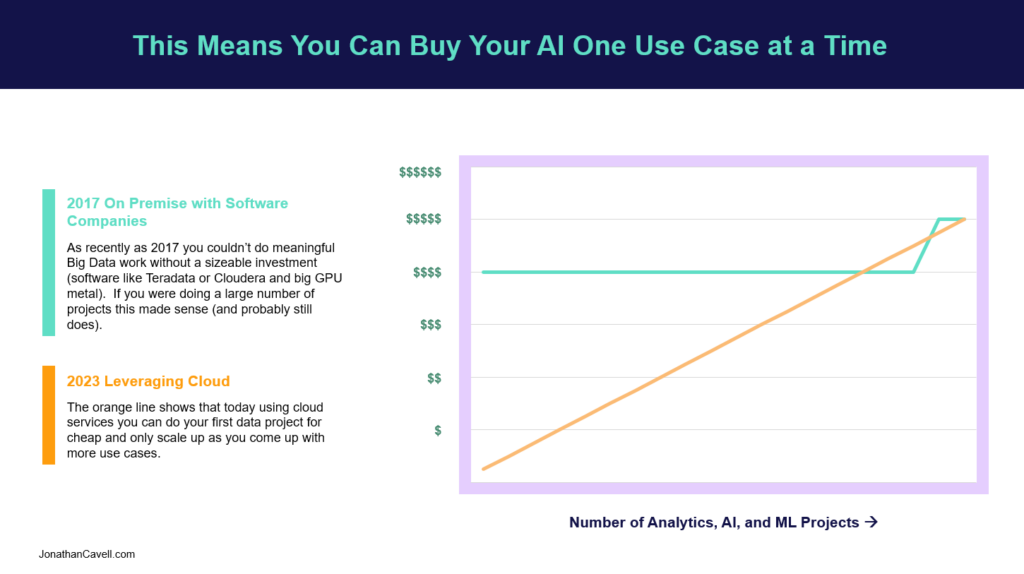
I told you that story to get to this one. This has enormous ramifications for firms that previously shyed away from getting into Big Data and AI because they couldn’t generate sufficient ROI from their use cases to offset the giant costs of specialized hardware and software. Because the Cloud Providers charge by the hour for what you actually use, the initial barrier to entry around hardware and software purchasing is nearly completely gone. You can create a project budget for an individual initiative even if you only have one use case.
I attempted to illustrate this in the chart above, “This means you can buy AI Use Cases One at a Time”. As with most things in the cloud, if you have sufficient workload, and can manage it efficiently, it is often cheaper to run on premise. Where this is transformative is for organizations that only have a few Big Data use cases either because of their size or because of their industry.